Amazon S3 is great for storing any type of binary data or file you can need in a centralized location in the cloud. There is a dedicated URL for each object, which can be easily shared with anyone that needs to access it.
However, say that your bucket is storing private/proprietary information. You wouldn't want just anybody to be able to retrieve that data with an HTTP request, would you? In this blog, we'll explore how we can securely and efficiently access S3 objects with either direct AWS or 3rd-party autentication/authorization.
Bucket Policies
Bucket policies are the first step to restricting public access to objects. They apply to entire buckets in S3, and can be set up to only allow certain AWS IAM users, user roles, or methods of access to retrieve objects within the bucket it's applied to.
Here's a straigtforward bucket policy to restrict any access to an S3 bucket except for those that provide IAM credentials which match to a specific user:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::ACCOUNT_ID:user/USER_NAME"
},
"Action": ]
"s3:GetObject"
[,
"Resource": ]
"arn:aws:s3:::BUCKET_NAME/*"
[
}
]
}
Now this solution works for any situation where the client fetching the S3 object is able to provide permanent IAM credentials in their request. However, this is very rarely a valid solution. What if we have an existing authentication solution which we want to use to determine access to a S3 object? Or what if we don't want/need to edit this policy whenever a new user needs access?
Accomodating 3rd-party Authentication
To abstract the IAM authentication layer entirely, we could proxy the S3 files through some intermediate compute resource within our VPC that:
- can authenticate a request with a 3rd party auth solution.
- can access the buckets directly, with its own static set of IAM credentials.
Below is a diagram of this dataflow. Only the solid lines are data transfers that contain the data of the S3 object being requested.
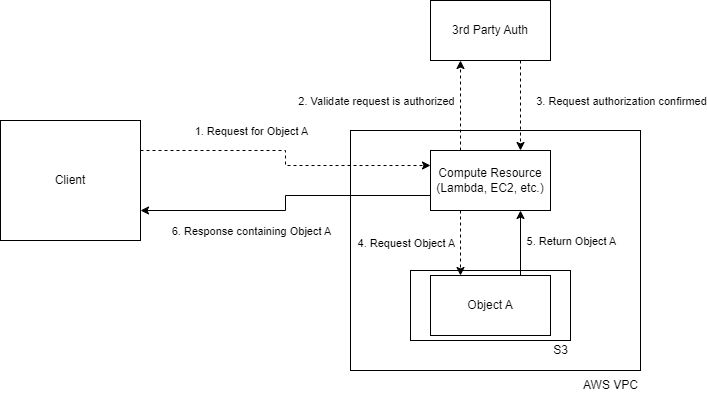
This is, strictly speaking, an effective solution. However, S3 objects can be very large, so passing the whole object through some intermediary compute resource may incur unacceptable memory/data transfer costs. What we'd want is a way to securely access the S3 object while still being able to pull it directly from the bucket to the end client making the request, in order to take advantage of S3's ultra-cost-efficient retrieval pricing.
Enter - the presigned URL!
Presigned URLs are used to temporarily authorize operations across AWS to anybody who has the URL. To generate a presigned URL for a specific action, your IAM policy must be authorized to perform that action. To mitigate the chance that the power of a presigned URL falls into the wrong hands, they are configured to only serve their purpose for a defined timeout.
Using presigned URLs generated to provide access to individual S3 objects at request time, we can extend the secure access approach above, such that:
- The client sends an authenticated request using the 3rd-party auth to a compute resource (lambda works perfectly) with full read-access to our S3 bucket.
- The compute resource authenticates this request against 3rd party auth.
- The compute resource generates a pre-signed URL for the S3 object requested and returns it to the client.
- The client fetches the S3 object using the presigned URL before it times out.
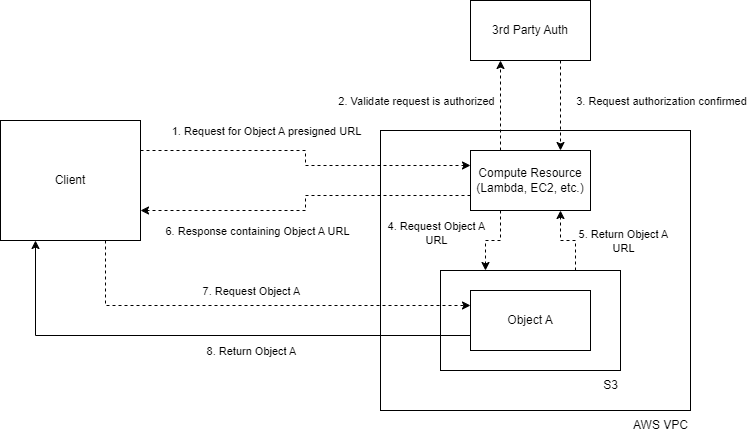
Notice how the file is requested directly from S3 in this setup! With that, we have a secure and performant solution.
To see an example implementation of this design, see my follow-up post, Embedding private media files securely in a React frontend with Amazon S3 and AWS Lambda.
Ready to take your Application Development project to the next level? Contact us today to learn more about our solutions!